Selenium学习笔记
简介
本文借鉴了b站up白月黑羽的Selenium教学文档,对于其中内容进行总结修改cv等操作整合为这篇便于我进行复习的文档,感谢开源大佬。
Selenium是目前主流的web浏览器自动化方案,通过他我们可以写出自动化程序,让他帮我们操作浏览器,就像你小时候玩部落冲突用红手指里面的游戏脚本,帮你刷经济那样,自动进行控制。
他还可以爬去网页数据,从web界面获取信息,然后在用程序进行分析处理。
自动化原理图如下:
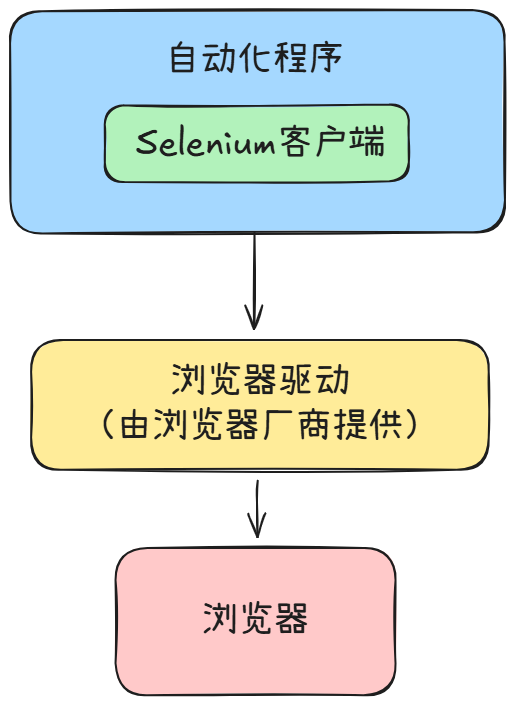
大概解释一下,Selenium的自动化执行流程:
- 自动化程序调用Selenium 客户端库函数(比如点击按钮元素)
- 客户端库会发送Selenium 命令 给浏览器的驱动程序
- 浏览器驱动程序接收到命令后 ,驱动浏览器去执行命令
- 浏览器执行命令
- 浏览器驱动程序获取命令执行的结果,返回给我们自动化程序
- 自动化程序对返回结果进行处理
消息收发是通过Selenium客户端库底层封装好的,我们只需要进行调用即可,不同的编程语言,官方有对应的库来方便开发者使用。
安装使用方面:
环境安装需要三个东西,Selenium客户端库,浏览器驱动,浏览器。
客户端库方面对于Python直接用pip命令进行安装即可,
pip install selenium
安装慢就可以使用国内清华大学源
pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple
浏览器驱动现在新版Python Selenium客户端库内置了一个selenium manager 工具,运行时他会帮我们自动下载浏览器驱动和浏览器。
但是需要注意国内的网络原因,不然下载速度会很慢或者直接下载失败,可以通过手动配置镜像,或者手动下载在安装来解决。
set SE_DRIVER_MIRROR_URL=https://cdn.npmmirror.com/binaries/chrome-for-testing
上述代码可以给当前命令窗口设置临时的环境变量镜像。
我在项目虚拟环境中安装Selenium客户端,导入依赖Pycharm报错提示未找到,这是因为我没有切换我的解释器,我仍然使用的是我的全局Python解释器,而不是我虚拟环境中安装了Selenium客户端库的解释器,在设置里添加一下就好了。
安装好了以后编写了一个简单的示例如下
from selenium import webdriver
# 创建webdriver对象
web = webdriver.Edge()
#打开我的博客网站
web.get('https://www.geekrain.site')
#程序运行完成之后会自动关闭浏览器,就是很多人说的闪退
#这里加上一个等待用户输入,防止闪退
input('按回车退出')
#关闭浏览器窗口
web.quit()
感觉这个成就感比我写出后端哪些增删改查接口要大,这就是控制的感觉吗。感觉我从小不管是玩游戏还是玩玩具都喜欢那种能自行操控的东西,比如游戏里的坦克,坐骑,现实生活里的小汽车,无人机,还有游戏脚本,还记得当时玩bekemmo那个游戏,自己用一键玩脚本简单的写了一个刷经验的脚本,看着他动起来真的很开心,真是怀念呀,当时还是超级破烂手机,电池也不行,屏幕也碎了,还没有root,要装一个虚拟机在那个虚拟环境里才有root权限可以弄脚本,手机给我搞得超级烫,那时候就挺喜欢折腾了。
小问题:
1.关闭日志
写好自动化程序之后,在终端运行打印出很多浏览器驱动发出的日志,大部分都是无用的可以这样关闭
可以这样关闭
from selenium import webdriver
# 加上参数,禁止 chromedriver 日志写屏
options = webdriver.ChromeOptions()
options.add_experimental_option(
'excludeSwitches', ['enable-logging'])
# 这里指定 options 参数
wd = webdriver.Chrome(options=options)
Edge浏览器驱动,也可以使用这个参数,比如
wd = webdriver.Edge(options=options)
2.病毒重置
有的朋友的电脑上Selenium自动化时,浏览器会弹出防病毒重置设置,解决方法如下
- 命令行输入
regedit,运行注册表编辑器 - 在左边的目录树找到
HKEY_CURRENT_USER\Software\Google\Chrome - 删除其下的
TriggeredReset子项 - 关闭 注册表编辑器
选择元素的基本方法
自动化的操作重要的就是定位元素,元素定位之后执行相关的自动化操作,所以这一部分是重点,感觉和前端css样式里面一样,里面的选择器语法也是很重要的部分。
在浏览器上选择元素的方法
使用F12开发者工具,快捷键ctrl + shift + c后可以通过鼠标来选定元素,会给出页面的源码。
除了上面的方法,还可以选择元素之后邮件,点击检查选项也可以实现。
根据ID属性选择元素
很多元素,为了更好的操作,定义css样式,会添加id属性,我们可以根据这个id属性来定位页面元素,使用方法如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
# 创建webdriver对象
web = webdriver.Edge()
#访问网址
web.get('https://www.byhy.net/cdn2/files/selenium/stock1.html')
#定位页面元素位置
element = web.find_element(By.ID,'kw')
#键入信息
element.send_keys('通讯')
input('输入回车关闭浏览器页面')
#关闭浏览器窗口
pass
浏览器 找到id为kw的元素后,将结果通过 浏览器驱动 返回给 自动化程序, 所以 find_element 方法会 返回一个 WebElement 类型的对象。
这个WebElement 对象可以看成是对应 页面元素的遥控器。
我们通过这个WebElement对象,就可以操控 对应的界面元素。
但是如果没有这个传入的Id,找不到元素,就会抛出selenium.common.exceptions.NoSuchElementException,在一些特殊场景,可以补货该异常来执行后续操作。
根据Class属性选择元素
勾起了我学习前端时的记忆,有时候一些元素属于同一种类型,就用class属性来进行分类,形式如下:
<body>
<div class="plant"><span>土豆</span></div>
<div class="plant"><span>洋葱</span></div>
<div class="plant"><span>白菜</span></div>
<div class="animal"><span>狮子</span></div>
<div class="animal"><span>老虎</span></div>
<div class="animal"><span>山羊</span></div>
</body>
如果我们要选中所有的动物元素,就可以像这样写:wd.find_elements(By.CLASS_NAME, 'animal')
find_elements 返回的是找到的符合条件的 所有 元素 (这里有3个元素), 放在一个 列表 中返回。
而如果我们使用 wd.find_element (注意少了一个s) 方法, 就只会返回第一个元素.
演示代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
# 创建webdriver对象
web = webdriver.Edge()
web.get('https://www.byhy.net/cdn2/files/selenium/sample1.html')
#程序运行完成之后会自动关闭浏览器,就是很多人说的闪退
#获取Class属性为动物的信息
elements = web.find_elements(By.CLASS_NAME,'animal')
#获取输入框
shuru = web.find_element(By.ID,'searchtext')
#便利动物信息然后输入到输入框中
for elements in elements:
shuru.send_keys(elements.text)
#这里加上一个等待用户输入,防止闪退
input('输入回车')
#关闭浏览器窗口
pass
Class类型定义的时候,不知可以定义多个,就那一个人来举例人可以有多个标签,中国人 ,学生,青少年这种,这时候如果我们选择到这种有多个Class属性的元素,只要指定其中一个属性就可以选到这个元素
<span class="chinese student">张三</span>
我们要用代码选择这个元素,可以指定任意一个class 属性值,都可以选择到这个元素,如下
element = wd.find_elements(By.CLASS_NAME,'chinese')
或者
element = wd.find_elements(By.CLASS_NAME,'student')
而不能这样写
element = wd.find_elements(By.CLASS_NAME,'chinese student')
根据Tag名选择元素
Tag就是标签属性例如div,span这种。
类似的,我们可以通过指定 参数为 By.TAG_NAME ,选择所有的tag名为 div的元素,如下所示
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://www.byhy.net/cdn2/files/selenium/sample1.html')
# 根据 tag name 选择元素,返回的是 一个列表
# 里面 都是 tag 名为 div 的元素对应的 WebElement对象
elements = wd.find_elements(By.TAG_NAME, 'div')
# 取出列表中的每个 WebElement对象,打印出其text属性的值
# text属性就是该 WebElement对象对应的元素在网页中的文本内容
for element in elements:
print(element.text)
input('按回车退出')
findelement和findelements的区别
使用 find_elements 选择的是符合条件的 所有 元素, 如果没有符合条件的元素, 返回空列表
使用 find_element 选择的是符合条件的 第一个 元素, 如果没有符合条件的元素, 抛出 NoSuchElementException 异常
通过WebElement对象选择元素
WebDriver对象现有选择元素的方法,Webelement对象也有选择元素的方法,选择的范围有区别
WebDriver:选择范围是整个web页面
WebElement:选择范围是这个元素的内部(他也可以调用findelements,findelements这些方法)
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://www.byhy.net/cdn2/files/selenium/sample1.html')
element = wd.find_element(By.ID,'container')
# 限制 选择元素的范围是 id 为 container 元素的内部。
spans = element.find_elements(By.TAG_NAME, 'span')
for span in spans:
print(span.text)
input('按回车退出')
等待元素出现
在一些时候,比如查询数据的情况,数据并不能第一时间就被获取然显示到页面,中间是有一定时间隔的,要从数据库查,也可能会受送到网速的影响。如果这时候调用元素查找,会报未找到元素的异常错误NoSuchElementException 。
除了最简单的使用时间函数让程序在点击查询之后休眠一定时间,弊端也显而易见,你并不能确定等待的时间是多少。
Selenium提供了一个合理的解决方法,隐式等待:
原理就是当发现元素没有找到的时候,并不是立即返回找不到的错误,而是执行一个循环以半秒为一个周期重新查找,直到找到那个元素,或者在等到超过最大等待时间抛出未找到错误(如果是find_elements之类的方法,则是返回一个空列表)
该方法接受一个参数, 用来指定 最大等待时长。
wd.implicitly_wait(10)
小贴士:一般在创建了WebDriver对象之后,就可以在后后面加上这句隐式等待方法。
并不是有了这个方法,time.sleep()这个函数就没有用处了,impolcitly_wait这个函数他只会在元素没找到的时候执行,在一些特殊情况,比如下拉列表,元素是存在的,只是因为点击的时候页面渲染差了一点时间没有找到对应的元素就会报错,这个时候就要,自己定义休眠时间,让程序停下来一会儿。
操作元素的基本方法
获取到我们想要的元素之后,代码就会返回WebElement对象,通过这个对象,我们就可以操控元素了
操作通常包括:
- 点击元素
- 在元素中输入字符串
- 获取元素包含的信息,例如文本内容,元素的属性
点击元素
调用WebElement对象的click方法
调用这个方法,浏览器接受自动化命令点击的是该元素的中心点位置。
输入框
调用元素WebElement对象的send_keys方法
如果要吧输入框中已经有的内容清除掉,则使用WebElement对象的clear方法
获取元素信息
获取元素的文本内容
上一章,我们已经知道,通过WebElement对象的 text 属性,可以获取元素 展示在界面上的 文本内容。
比如
element = wd.find_element(By.ID, 'animal')
print(element.text)
获取元素属性
通过WebElement对象的 get_attribute 方法来获取元素的属性值
比如要获取元素属性class的值,就可以使用 element.get_attribute('class')
如下:
element = wd.find_element(By.ID, 'input_name')
print(element.get_attribute('class'))
执行完自动化代码,如果想关闭浏览器窗口可以调用WebDriver对象的 quit 方法,像这样 wd.quit()
获取整个元素对应的HTML
要获取整个元素对应的HTML文本内容,可以使用 element.get_attribute('outerHTML')
如果,只是想获取某个元素 内部 的HTML文本内容,可以使用 element.get_attribute('innerHTML')
获取输入框里面的文字
对于input输入框的元素,要获取里面的输入文本,用text属性是不行的,这时可以使用 element.get_attribute('value')
比如
element = wd.find_element(By.ID, "input1")
print(element.get_attribute('value')) # 获取输入框中的文本
获取元素文本内容2
通过WebElement对象的 text 属性,可以获取元素 展示在界面上的 文本内容。
但是,有时候,元素的文本内容没有展示在界面上,或者没有完全完全展示在界面上。 这时,用WebElement对象的text属性,获取文本内容,就会有问题。
出现这种情况,可以尝试使用 element.get_attribute('innerText') ,或者 element.get_attribute('textContent')
使用 innerText 和 textContent 的区别是,前者只显示元素可见文本内容,后者显示所有内容(包括display属性为none的部分)
CSS表达式基础
在我自己做了一些练习之后,我深刻的认识到普通元素选择的局限性,遇到复杂的页面,要选到对应的元素非常繁琐,还有一种无从下手之感,前端中可以通过
Css selector(选择器) 语法选择元素,那么自然在自动化中也可以使用这个语法来确定元素(熟悉的感觉,仿佛回到当时打比赛库库写前端页面的时候,虽然也没啥用)。
根据 tag名、id、class 选择元素
CSS Selector 同样可以根据tag名、id 属性和 class属性 来 选择元素,
根据 tag名 选择元素的 CSS Selector 语法非常简单,直接写上tag名即可,
比如 要选择 所有的tag名为div的元素,就可以是这样
elements = wd.find_elements(By.CSS_SELECTOR, 'div')
等价于
elements = wd.find_elements(By.TAG_NAME, 'div')
根据id属性 选择元素的语法是在id号前面加上一个井号: #id值
比如 请点击打开这个网址
有下面这样的元素:
<input type="text" id='searchtext' />
就可以使用 #searchtext 这样的 CSS Selector 来选择它。
比如,我们想在 id 为 searchtext 的输入框中输入文本 你好 ,完整的Python代码如下
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://www.byhy.net/cdn2/files/selenium/sample1.html')
element = wd.find_element(By.CSS_SELECTOR, '#searchtext')
element.send_keys('你好')
根据class属性 选择元素的语法是在 class 值 前面加上一个点: .class值
要选择所有 class 属性值为 animal的元素 动物 除了这样写
elements = wd.find_elements(By.CLASS_NAME, 'animal')
还可以这样写
elements = wd.find_elements(By.CSS_SELECTOR, '.animal')
因为是选择 所有 符合条件的 ,所以用 find_elements 而不是 find_element
总的来说就是Tag 直接输入,标签名 Class 前面加个.然后输入class名,id的话输入之前加个#号
选择子元素和后代元素
简单比喻一下,这个子元素和后代元素以及父元素他们的关系可以想象成一个笔袋,最大的元素是笔袋,笔袋里面直接的装了很多笔,这些笔称之为笔袋的子元素,而中性笔里面又装着可替换式的笔芯,笔芯就是笔袋的后代元素,笔袋则是笔芯的祖宗元素。
语法规则如下。
如果 元素2 是 元素1 的 直接子元素, CSS Selector 选择子元素的语法是这样的
元素1 > 元素2
中间用一个大于号 (我们可以理解为箭头号)
注意,最终选择的元素是 元素2, 并且要求这个 元素2 是 元素1 的直接子元素
也支持更多层级的选择, 比如
元素1 > 元素2 > 元素3 > 元素4
就是选择 元素1 里面的子元素 元素2 里面的子元素 元素3 里面的子元素 元素4 , 最终选择的元素是 元素4
如果 元素2 是 元素1 的 后代元素, CSS Selector 选择后代元素的语法是这样的
元素1 元素2
中间是一个或者多个空格隔开
最终选择的元素是 元素2 , 并且要求这个 元素2 是 元素1 的后代元素。
也支持更多层级的选择, 比如
元素1 元素2 元素3 元素4
最终选择的元素是 元素4
CSS 支持 大于号和 空格 混合使用,比如
元素1 > 元素2 元素3 > 元素4
其中每个元素的写法 可以是 复合写法 ,比如
span.date // 选择 class 值有 date 的 span 元素
div#bottom // 选择 id 为 bottom 的 div 元素
div#bottom.date // 选择 id 为 bottom, class 值有 date, 的 div 元素
根据属性选择
简单来说的作用是能通过HTML标签内部的“属性”和“属性值”来进行定位。
id、class 都是web元素的 属性 ,因为它们是很常用的属性,所以css选择器专门提供了根据 id、class 选择的语法。
那么其他的属性呢?
<a href="http://www.miitbeian.gov.cn">苏ICP备88885574号</a>
里面根据 href选择,可以用css 选择器吗?
当然可以!
css 选择器支持通过任何属性来选择元素,语法是用一个方括号 [] 。
比如要选择上面的a元素,就可以使用 [href="http://www.miitbeian.gov.cn"] 。
这个表达式的意思是,选择 属性href值为 http://www.miitbeian.gov.cn 的元素。
完整代码如下
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://www.byhy.net/cdn2/files/selenium/sample1.html')
# 根据属性选择元素
element = wd.find_element(By.CSS_SELECTOR, '[href="http://www.miitbeian.gov.cn"]')
# 打印出元素对应的html
print(element.get_attribute('outerHTML'))
当然,前面可以加上标签名的限制,比如 div[class='SKnet'] 表示 选择所有 标签名为div,且class属性值为SKnet的元素。
属性值用单引号,双引号都可以。
根据属性选择,还可以不指定属性值,比如 [href] , 表示选择 所有 具有 属性名 为href 的元素,不管它们的值是什么。
CSS 还可以选择 属性值 包含 某个字符串 的元素
比如, 要选择a节点,里面的href属性包含了 miitbeian 字符串,就可以这样写
a[href*="miitbeian"]
还可以 选择 属性值 以某个字符串 开头 的元素
比如, 要选择a节点,里面的href属性以 http 开头 ,就可以这样写
a[href^="http"]
还可以 选择 属性值 以某个字符串 结尾 的元素
比如, 要选择a节点,里面的href属性以 gov.cn 结尾 ,就可以这样写
a[href$="gov.cn"]
如果一个元素具有多个属性
<div class="misc" ctype="gun">沙漠之鹰</div>
CSS 选择器 可以指定 选择的元素要 同时具有多个属性的限制,像这样 div[class=misc][ctype=gun]
在使用来使用累不属性的时候如果想根据value获取到对应元素,需要这个元素本生就含有value这个属性,而不是被元素标签包裹的文本内容,如果是后者,那么就不能通过value找到元素。
验证选择语法是否输入正确选到了我们需要的元素
打开开发者工具在元素页面使用快捷键ctrl + f 就可以打开一个输入框,在里面键入Css selector语法就可以验证自己输的对不对。
CSS表达式进阶
有点意思
组选择
如果想要同时选择class为plant和calss为animal的元素
可以使用逗号 , 隔开形如:
.plant , .animal
按次序选择子节点
这个我之前犯了很大一个错误,举个例子
span:nth-child(2)
这句的意思我以前都是认为找span节点的第二个节点
但实际上意思是,找到所有子节点的第二个节点,且该节点元素必须是span
如果想要实现上一句话的操作正确的语句应该是
span:nth-of-type(2)
感觉这个我还会混淆,重点记忆。
父元素的倒数第n个子节点
比如:
p:nth-last-child(1)
就是选择第倒数第1个子元素,并且是p元素
父元素的第几个某类型的子节点
就是我上面提了一嘴的,
我们可以指定选择的元素 是父元素的第几个 某类型的 子节点
使用 nth-of-type
比如,
我们要选择 唐诗 和宋词 的第一个 作者,
可以像上面那样思考:选择的是 第2个子元素,并且是span类型
所以这样可以这样写 span:nth-child(2) ,
还可以这样思考,选择的是 第1个span类型 的子元素
所以也可以这样写 span:nth-of-type(1)
父元素的倒数第几个某类型的子节点
当然也可以反过来, 选择父元素的 倒数第几个某类型 的子节点
使用 nth-last-of-type
像这样
p:nth-last-of-type(2)
奇数节点和偶数节点
如果要选择的是父元素的 偶数节点,使用 nth-child(even)
比如
p:nth-child(even)
如果要选择的是父元素的 奇数节点,使用 nth-child(odd)
p:nth-child(odd)
如果要选择的是父元素的 某类型偶数节点,使用 nth-of-type(even)
如果要选择的是父元素的 某类型奇数节点,使用 nth-of-type(odd)
相邻兄弟节点选择
上面的例子里面,我们要选择 唐诗 和宋词 的第一个 作者
还有一种思考方法,就是选择 h3 后面紧跟着的兄弟节点 span。
这就是一种 相邻兄弟 关系,可以这样写 h3 + span
表示元素 紧跟关系的 是 加号
后续所有兄弟节点选择
如果要选择是 选择 h3 后面所有的兄弟节点 span,可以这样写 h3 ~ span
Frame切换
在Html文档中,frame元素h和iframe元素比较特殊,左右同时嵌入另一份Html文档,简单来说就是网页嵌入,在使用Selenium操作网页的时候默认是操作最外层的Html,并不包含被嵌入的Htm文档内容,如果这时候要锁定被嵌入的HTML文档中的元素就要切换操作范围到被嵌入的文档中去
使用WebDriver对象的switch_to属性,
wd.switch_to.frame('frame_reference')
其中, frame_reference 可以是 frame 元素的属性 name 或者 ID 。
比如这里,就可以填写 iframe元素的id 'frame1' 或者 name属性值 'innerFrame'。
像这样
wd.switch_to.frame('frame1')
或者
wd.switch_to.frame('innerFrame')
也可以填写frame 所对应的 WebElement 对象。
我们可以根据frame的元素位置或者属性特性,使用find系列的方法,选择到该元素,得到对应的WebElement对象
比如,这里就可以写
wd.switch_to.frame(wd.find_element(By.TAG_NAME, "iframe"))
然后,就可以进行后续操作frame里面的元素了。
上面的例子的正确代码如下
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://www.byhy.net/cdn2/files/selenium/sample2.html')
# 先根据name属性值 'innerFrame',切换到iframe中
wd.switch_to.frame('innerFrame')
# 根据 class name 选择元素,返回的是 一个列表
elements = wd.find_elements(By.CLASS_NAME, 'plant')
for element in elements:
print(element.text)
如果我们已经切换到某个iframe里面进行操作了,那么后续选择和操作界面元素 就都是在这个frame里面进行的。
这时候,如果我们又需要操作 主html (我们把最外层的html称之为 主html ) 里面的元素了呢?
怎么切换回原来的 主html 呢?
很简单,写如下代码即可
wd.switch_to.default_content()
例如,在上面 代码 操作完 frame里面的元素后, 需要 点击 主html 里面的按钮,就可以这样写
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://www.byhy.net/cdn2/files/selenium/sample2.html')
# 先根据name属性值 'innerFrame',切换到iframe中
wd.switch_to.frame('innerFrame')
# 根据 class name 选择元素,返回的是 一个列表
elements = wd.find_elements(By.CLASS_NAME, 'plant')
for element in elements:
print(element.text)
# 切换回 最外部的 HTML 中
wd.switch_to.default_content()
# 然后再 选择操作 外部的 HTML 中 的元素
wd.find_element_by_id('outerbutton').click()
wd.quit()
窗口切换
在一些网页中会遇到一些页面跳转按钮,这个时候,WebDriver对象还是老窗口对象,自动化操作也还是在老窗口进行
如果我们想要切换到新的窗口
可以使用Webdriver对象的switch_to属性的 window方法,如下所示:
wd.switch_to.window(handle)
其中,参数handle需要传入什么呢?
WebDriver对象有window_handles 属性,这是一个列表对象, 里面包括了当前浏览器里面所有的窗口句柄。
所谓句柄,大家可以想象成对应网页窗口的一个ID,
那么我们就可以通过 类似下面的代码,
for handle in wd.window_handles:
# 先切换到该窗口
wd.switch_to.window(handle)
# 得到该窗口的标题栏字符串,判断是不是我们要操作的那个窗口
if 'Bing' in wd.title:
# 如果是,那么这时候WebDriver对象就是对应的该该窗口,正好,跳出循环,
break
上面代码的用意就是:
我们依次获取 wd.windowhandles 里面的所有 句柄 对象, 并且调用 wd.switchto.window(handle) 方法,切入到每个窗口,
然后检查里面该窗口对象的属性(可以是标题栏,地址栏),判断是不是我们要操作的那个窗口,如果是,就跳出循环。
同样的,如果我们在新窗口 操作结束后, 还要回到原来的窗口,该怎么办?
我们可以仍然使用上面的方法,依次切入窗口,然后根据 标题栏 之类的属性值判断。
还有更省事的方法。
因为我们一开始就在 原来的窗口里面,我们知道 进入新窗口操作完后,还要回来,可以事先 保存该老窗口的 句柄,使用如下方法
# mainWindow变量保存当前窗口的句柄
mainWindow = wd.current_window_handle
切换到新窗口操作完后,就可以直接像下面这样,将driver对应的对象返回到原来的窗口
#通过前面保存的老窗口的句柄,自己切换到老窗口
wd.switch_to.window(mainWindow)
选择框
常见HTML选择框有:radio、checkbox、select框
redio
radio框选择选项,直接用WebElement的click方法,模拟用户点击就可以了。
比如, 我们要在下面的html中:
- 先打印当前选中的老师名字
- 再选择 小雷老师
<div id="s_radio">
<input type="radio" name="teacher" value="小江老师">小江老师<br>
<input type="radio" name="teacher" value="小雷老师">小雷老师<br>
<input type="radio" name="teacher" value="小凯老师" checked="checked">小凯老师
</div>
对应的代码如下
# 获取当前选中的元素
element = wd.find_element(By.CSS_SELECTOR,
'#s_radio input[name="teacher"]:checked')
print('当前选中的是: ' + element.get_attribute('value'))
# 点选 小雷老师
wd.find_element(By.CSS_SELECTOR,
'#s_radio input[value="小雷老师"]').click()
其中 #s_radio input[name="teacher"]:checked 里面的 :checked 是CSS伪类选择
表示选择 checked 状态的元素,对 radio 和 checkbox 类型的input有效
checkbox框
对checkbox进行选择,也是直接用 WebElement 的 click 方法,模拟用户点击选择。
需要注意的是,要选中checkbox的一个选项,必须 先获取当前该复选框的状态 ,如果该选项已经勾选了,就不能再点击。否则反而会取消选择。
比如, 我们要在下面的html中:选中 小雷老师
<div id="s_checkbox">
<input type="checkbox" name="teachers1" value="小江老师">小江老师<br>
<input type="checkbox" name="teachers1" value="小雷老师">小雷老师<br>
<input type="checkbox" name="teachers1" value="小凯老师" checked="checked">小凯老师
</div>
我们的思路可以是这样:
- 先把 已经选中的选项全部点击一下,确保都是未选状态
- 再点击 小雷老师
示例代码
# 先把 已经选中的选项全部点击一下
elements = wd.find_elements(By.CSS_SELECTOR,
'#s_checkbox input[name="teachers1"]:checked')
for element in elements:
element.click()
# 再点击 小雷老师
wd.find_element(By.CSS_SELECTOR,
"#s_checkbox input[value='小雷老师']").click()
select框
radio框及checkbox框都是input元素,只是里面的type不同而已。
select框 则是一个新的select标签,大家可以对照浏览器网页内容查看一下
对于Select 选择框, Selenium 专门提供了一个 Select类 进行操作,可以这样导入
from selenium.webdriver.support.select import Select
这个类实例化时传入 Select元素对应的 WebElement 对象,比如
select = Select(wd.find_element(By.ID, 'ss_single'))
Select类 提供了如下常用的 属性 和 方法
- allselectedoptions
返回所有 当前选中的option元素 对应的 WebElement 对象
比如
for ele in select.all_selected_options:
print(ele.text)
- selectbyvalue
根据选项的 value属性值 ,选择元素。
比如,下面的HTML,
<option value="foo">Bar</option>
就可以根据 foo 这个值选择该选项,
select.select_by_value('foo')
- selectbyindex
根据选项的 次序 选择元素
现在Selenium 4 是从 0 开始, 第一个选项 index 为 0
select_by_index(0) ,选择的是 第 1 个选项,
select_by_index(1) ,选择的是 第 2 个选项, 依此类推
以前,老版本的 Seleium,是从 1 开始
- selectbyvisible_text
根据选项的 可见文本 ,选择元素。
比如,下面的HTML,
<option value="foo">Bar</option>
就可以根据 Bar 这个内容,选择该选项
select.select_by_visible_text('Bar')
- deselectbyvalue
根据选项的value属性值, 去除 选中元素
- deselectbyindex
根据选项的次序,去除 选中元素
- deselectbyvisible_text
根据选项的可见文本,去除 选中元素
- deselect_all
去除 选中所有元素
Select单选框
对于 select单选框,操作比较简单:
不管原来选的是什么,直接用Select方法选择即可。
例如,选择示例里面的小雷老师,示例代码如下
# 导入Select类
from selenium.webdriver.support.select import Select
# 创建Select对象
select = Select(wd.find_element(By.ID, "ss_single"))
# 通过 Select 对象选中小雷老师
select.select_by_visible_text("小雷老师")
Select多选框
对于select多选框,要选中某几个选项,要注意去掉原来已经选中的选项。
例如,我们选择示例多选框中的 小雷老师 和 小凯老师
可以用select类 的deselect_all方法,清除所有 已经选中 的选项。
然后再通过 selectbyvisible_text方法 选择 小雷老师 和 小凯老师。
示例代码如下:
# 导入Select类
from selenium.webdriver.support.select import Select
# 创建Select对象
select = Select(wd.find_element(By.ID, "ss_multi"))
# 清除所有 已经选中 的选项
select.deselect_all()
# 选择小雷老师 和 小凯老师
select.select_by_visible_text("小雷老师")
select.select_by_visible_text("小凯老师")
其他操作
有别余上面的一些特殊操作方法和技巧
特殊元素操作
比如 鼠标右键点击、双击、移动鼠标到某个元素、鼠标拖拽等。
这些操作,可以通过 Selenium 提供的 ActionChains 类来实现。
ActionChains 类 里面提供了 一些特殊的动作的模拟,我们可以通过 ActionChains 类的代码查看到,如下所示
image
示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
wd = webdriver.Chrome()
wd.implicitly_wait(5)
wd.get('https://www.byhy.net/cdn2/files/selenium/sample4.html')
from selenium.webdriver.common.action_chains import ActionChains
ac = ActionChains(wd)
time.sleep(3)
# 光标悬停 到元素上
ac.move_to_element(
wd.find_element(By.CSS_SELECTOR, '.navbar-nav > li.dropdown')
).perform()
time.sleep(3)
# 拖放元素
for i in range(1,6):
ac.drag_and_drop(
wd.find_element(By.ID, f'course-{i}'),
wd.find_element(By.ID,'selected-courses')
).perform()
time.sleep(0.5)
input('\n\n按回车退出')
直接执行javascript
我们可以直接让浏览器运行一段javascript代码,并且得到返回值,如下
# 直接执行 javascript,里面可以直接用return返回我们需要的数据
nextPageButtonDisabled = driver.execute_script(
'''
ele = document.querySelector('.soupager > button:last-of-type');
return ele.getAttribute('disabled')
''')
# 返回的数据转化为Python中的数据对象进行后续处理
if nextPageButtonDisabled == 'disabled': # 是最后一页
return True
else: # 不是最后一页
return False
有时,自动化的网页内容很长,或者很宽,超过一屏显示,
如果我们要点击的元素不在窗口可见区内,新版本的selenium协议, 浏览器发现要操作(比如点击操作)的元素,不在可见区内,往往会操作失败,
出现类似下面的提示
element click intercepted: Element <span>这里是元素html</span>
is not clickable at point (119, 10).
Other element would receive the click: <div>...</div>
这时,可以调用 execute_script 直接执行js代码,让该元素出现在窗口可见区正中
driver.execute_script("arguments[0].scrollIntoView({block:'center',inline:'center'})", job)
其中 arguments[0] 就指代了后面的第一个参数 job 对应的js对象,
js对象的 scrollIntoView 方法,就是让元素滚动到可见部分
block:'center' 指定垂直方向居中
inline:'center' 指定水平方向居中
冻结界面
一些网站的元素只有在你鼠标悬停的时候才会出现内容,移开内容就消失了,导致无法定位元素,这个时候可以使用下面的方法
在 开发者工具栏 console 里面执行如下js代码
setTimeout(function(){debugger}, 5000)
这句代码什么意思呢?
表示在 5000毫秒后,执行 debugger 命令
执行该命令会 浏览器会进入debug状态。 debug状态有个特性, 界面被冻住, 不管我们怎么点击界面都不会触发事件。
所以,我们可以在输入上面代码并回车 执行后, 立即 鼠标放在界面 右上角 更多产品处。
这时候,就会弹出功能图标。
然后,我们仔细等待 5秒 到了以后, 界面就会因为执行了 debugger 命令而被冻住。
然后,我们就可以点击 开发者工具栏的 查看箭头, 再去 点击 对应的图标 ,查看其属性了。
弹出对话框
弹出的对话框有三种类型,分别是 Alert(警告信息)、confirm(确认信息)和prompt(提示输入)
他们不同于页面的弹出对话框,在HTML文档中无法锁定其位置,这个时候需要使用专有的方法来获取信息进行操作。
Alert
Alert 弹出框,目的就是显示通知信息,只需用户看完信息后,点击 OK(确定) 就可以了。
那么,自动化的时候,代码怎么模拟用户点击 OK 按钮呢?
selenium提供如下方法进行操作
driver.switch_to.alert.accept()
👓 注意:如果我们不去点击它,页面的其它元素是不能操作的。
如果程序要获取弹出对话框中的信息内容, 可以通过 如下代码
driver.switch_to.alert.text
示例代码如下
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.implicitly_wait(5)
driver.get('https://www.byhy.net/cdn2/files/selenium/test4.html')
# --- alert ---
driver.find_element(By.ID, 'b1').click()
# 打印 弹出框 提示信息
print(driver.switch_to.alert.text)
# 点击 OK 按钮
driver.switch_to.alert.accept()
Confirm
Confirm弹出框,主要是让用户确认是否要进行某个操作。
比如:当管理员在网站上选择删除某个账号时,就可能会弹出 Confirm弹出框, 要求确认是否确定要删除。
Confirm弹出框 有两个选择供用户选择,分别是 OK 和 Cancel, 分别代表 确定 和 取消 操作。
那么,自动化的时候,代码怎么模拟用户点击 OK 或者 Cancel 按钮呢?
selenium提供如下方法进行操作
如果我们想点击 OK 按钮, 还是用刚才的 accept方法,如下
driver.switch_to.alert.accept()
如果我们想点击 Cancel 按钮, 可以用 dismiss方法,如下
driver.switch_to.alert.dismiss()
示例代码如下
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.implicitly_wait(5)
driver.get('https://www.byhy.net/cdn2/files/selenium/test4.html')
# --- confirm ---
driver.find_element(By.ID, 'b2').click()
# 打印 弹出框 提示信息
print(driver.switch_to.alert.text)
# 点击 OK 按钮
driver.switch_to.alert.accept()
driver.find_element(By.ID, 'b2').click()
# 点击 取消 按钮
driver.switch_to.alert.dismiss()
Prompt
出现 Prompt 弹出框 是需要用户输入一些信息,提交上去。
比如:当管理员在网站上选择给某个账号延期时,就可能会弹出 Prompt 弹出框, 要求输入延期多长时间。
可以调用如下方法
driver.switch_to.alert.send_keys()
示例代码如下
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.implicitly_wait(5)
driver.get('https://www.byhy.net/cdn2/files/selenium/test4.html')
# --- prompt ---
driver.find_element(By.ID, 'b3').click()
# 获取 alert 对象
alert = driver.switch_to.alert
# 打印 弹出框 提示信息
print(alert.text)
# 输入信息,并且点击 OK 按钮 提交
alert.send_keys('web自动化 - selenium')
alert.accept()
# 点击 Cancel 按钮 取消
driver.find_element(By.ID, 'b3').click()
alert = driver.switch_to.alert
alert.dismiss()
👓 注意:有些弹窗并非浏览器的alert 窗口,而是html元素,这种对话框,只需要通过之前介绍的选择器选中并进行相应的操作就可以了。
小技巧
一些可能会接触到但是不常用的功能,遇到不会可以上来看复习
窗口大小
有时间我们需要获取窗口的属性和相应的信息,并对窗口进行控制
- 获取窗口大小
driver.get_window_size()
- 改变窗口大小
driver.set_window_size(x, y)
获取当前窗口标题
浏览网页的时候,我们的窗口标题是不断变化的,可以使用WebDriver的title属性来获取当前窗口的标题栏字符串。
driver.title
获取当前窗口URL地址
driver.current_url
例如,访问网易,并获取当前窗口的标题和URL
from selenium import webdriver
driver = webdriver.Chrome()
driver.implicitly_wait(5)
# 打开网站
driver.get('https://www.163.com')
# 获取网站标题栏文本
print(driver.title)
# 获取网站地址栏文本
print(driver.current_url)
截屏
有的时候,我们需要把浏览器屏幕内容保存为图片文件。
比如,做自动化测试时,一个测试用例检查点发现错误,我们可以截屏为文件,以便测试结束时进行人工核查。
可以使用 WebDriver 的 getscreenshotas_file方法来截屏并保存为图片。
from selenium import webdriver
driver = webdriver.Chrome()
driver.implicitly_wait(5)
# 打开网站
driver.get('https://www.baidu.com/')
# 截屏保存为图片文件
driver.get_screenshot_as_file('1.png')
手机模式
我们可以通过 desired_capabilities 参数,指定以手机模式打开chrome浏览器
参考代码,如下
from selenium import webdriver
mobile_emulation = { "deviceName": "iPhone 14 Pro Max" }
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option("mobileEmulation", mobile_emulation)
driver = webdriver.Chrome(options=chrome_options)
driver.get('http://www.baidu.com')
input()
driver.quit()
上传文件
有时候,网站操作需要上传文件。
比如,著名的在线图片压缩网站: https://tinypng.com/
通常,网站页面上传文件的功能,是通过 type 属性 为 file 的 HTML input 元素实现的。
如下所示:
<input type="file" multiple="multiple">
使用selenium自动化上传文件,我们只需要定位到该input元素,然后通过 send_keys 方法传入要上传的文件路径即可。
如下所示:
# 先定位到上传文件的 input 元素
ele = wd.find_element(By.CSS_SELECTOR, 'input[type=file]')
# 再调用 WebElement 对象的 send_keys 方法
ele.send_keys(r'h:\g02.png')
如果需要上传多个文件,可以多次调用send_keys,如下
ele = wd.find_element(By.CSS_SELECTOR, 'input[type=file]')
ele.send_keys(r'h:\g01.png')
ele.send_keys(r'h:\g02.png')
但是,有的网页上传,是没有 file 类型 的 input 元素的。
如果是Windows上的自动化,可以采用 Windows 平台专用的方法:
执行
pip install pypiwin32
确保 pywin32 已经安装,然后参考如下示例代码
# 找到点击上传的元素,点击
driver.find_element(By.CSS_SELECTOR, '.dropzone').click()
sleep(2) # 等待上传选择文件对话框打开
# 直接发送键盘消息给 当前应用程序,
# 前提是浏览器必须是当前应用
import win32com.client
shell = win32com.client.Dispatch("WScript.Shell")
# 输入文件路径,最后的'\n',表示回车确定,也可能时 '\r' 或者 '\r\n'
shell.Sendkeys(r"h:\a2.png" + '\n')
sleep(1)
Xpath选择器
Xpath选择器和CSS选择器的功能一致,但是css选择器主要是给Htmlcss元素元素进行渲染的,而Xpath还有其他的应用场景,比如爬虫框架,手机app框架,这一部分的内容白夜黑羽大佬写的很详细,我就不多做改动,cv一下。
绝对路径选择
从根节点开始的,到某个节点,每层都依次写下来,每层之间用 / 分隔的表达式,就是某元素的 绝对路径
上面的xpath表达式 /html/body/div ,就是一个绝对路径的xpath表达式, 类似 css表达式 html>body>div
自动化程序要使用Xpath来选择web元素,使用 By.XPATH ,像这样:
elements = driver.find_elements(By.XPATH, "/html/body/div/select")
相对路径选择
有的时候,我们需要选择网页中某个元素, 不管它在什么位置 。
比如,选择示例页面的所有标签名为 div 的元素,如果使用css表达式,直接写一个 div 就行了。
那xpath怎么实现同样的功能呢? xpath需要前面加 // , 表示从当前节点往下寻找所有的后代元素,不管它在什么位置。
所以xpath表达式,应该这样写: //div
'//' 符号也可以继续加在后面,比如,要选择 所有的 div 元素里面的 所有的 p 元素 ,不管div 在什么位置,也不管p元素在div下面的什么位置,则可以这样写 //div//p
对应的自动化程序如下
elements = driver.find_elements(By.XPATH, "//div//p")
如果使用CSS选择器,对应代码如下
elements = driver.find_elements(By.CSS_SELECTOR,"div p")
如果,要选择 所有的 div 元素里面的 直接子节点 p , xpath,就应该这样写了 //div/p
如果使用CSS选择器,则为 div > p
通配符
如果要选择所有div节点的所有直接子节点,可以使用表达式 //div/*
*` 是一个通配符,对应任意节点名的元素,类似 CSS选择器 `div > *
代码如下:
elements = driver.find_elements(By.XPATH, "//div/*")
for element in elements:
print(element.get_attribute('outerHTML'))
根据属性选择
Xpath 可以根据属性来选择元素。
根据属性来选择元素 是通过 这种格式来的 [@属性名='属性值']
注意:
- 属性名注意前面有个@
- 属性值一定要用引号, 可以是单引号,也可以是双引号
根据id属性选择
选择 id 为 west 的元素,可以这样 //*[@id='west']
根据class属性选择
选择所有 select 元素中 class为 singlechoice 的元素,可以这样 `//select[@class='singlechoice']`
如果一个元素class 有多个,比如
<p id="beijing" class='capital huge-city'>
北京
</p>
如果要选 它, 对应的 xpath 就应该是 //p[@class="capital huge-city"]
不能只写一个属性,像这样 //p[@class="capital"] 则不行
根据其他属性
同样的道理,我们也可以利用其它的属性选择
比如选择 具有multiple属性的所有页面元素 ,可以这样 //*[@multiple]
属性值包含字符串
要选择 style属性值 包含 color 字符串的 页面元素 ,可以这样 //*[contains(@style,'color')]
要选择 style属性值 以 color 字符串 开头 的 页面元素 ,可以这样 //*[starts-with(@style,'color')]
要选择 style属性值 以 某个 字符串 结尾 的 页面元素 ,大家可以推测是 //*[ends-with(@style,'color')], 但是,很遗憾,这是xpath 2.0 的语法 ,目前浏览器都不支持
按次序选择
前面学过css表达式可以根据元素在父节点中的次序选择, 非常实用。
xpath也可以根据次序选择元素。 语法比css更简洁,直接在方括号中使用数字表示次序
比如
某类型 第几个 子元素
比如
要选择 p类型第2个的子元素,就是
//p[2]
注意,选择的是 p类型第2个的子元素 , 不是 第2个子元素,并且是p类型 。
注意体会区别
再比如,要选取父元素为div 中的 p类型 第2个 子元素
//div/p[2]
第几个子元素
也可以选择第2个子元素,不管是什么类型,采用通配符
比如 选择父元素为div的第2个子元素,不管是什么类型
//div/*[2]
某类型 倒数第几个 子元素
当然也可以选取倒数第几个子元素
比如:
- 选取p类型倒数第1个子元素
//p[last()]
- 选取p类型倒数第2个子元素
//p[last()-1]
- 选择父元素为div中p类型倒数第3个子元素
//div/p[last()-2]
范围选择
xpath还可以选择子元素的次序范围。
比如,
- 选取option类型第1到2个子元素
//option[position()<=2]
或者
//option[position()<3]
- 选择class属性为multi_choice的前3个子元素
//*[@class='multi_choice']/*[position()<=3]
- 选择class属性为multi_choice的后3个子元素
//*[@class='multi_choice']/*[position()>=last()-2]
为什么不是 last()-3 呢? 因为
last() 本身代表最后一个元素
last()-1 本身代表倒数第2个元素
last()-2 本身代表倒数第3个元素
组选择、父节点、兄弟节点
组选择
css有组选择,可以同时使用多个表达式,多个表达式选择的结果都是要选择的元素
css 组选择,表达式之间用 逗号 隔开
xpath也有组选择, 是用 竖线 隔开多个表达式
比如,要选所有的option元素 和所有的 h4 元素,可以使用
//option | //h4
等同于CSS选择器
option , h4
再比如,要选所有的 class 为 singlechoice 和 class 为 multichoice 的元素,可以使用
//*[@class='single_choice'] | //*[@class='multi_choice']
等同于CSS选择器
.single_choice , .multi_choice
选择父节点
xpath可以选择父节点, 这是css做不到的。
小贴士:实际上现在Css也可以选择父节点使用has(),就可以选择父节点,括号里面写,要找那个节点的父节点,使用起来没有Xpath方便,如果不限定反问,他会选择子节点的父节点的父节点....
某个元素的父节点用 /.. 表示
比如,要选择 id 为 china 的节点的父节点,可以这样写 //*[@id='china']/.. 。
当某个元素没有特征可以直接选择,但是它有子节点有特征, 就可以采用这种方法,先选择子节点,再指定父节点。
还可以继续找上层父节点,比如 //*[@id='china']/../../..
兄弟节点选择
前面学过 css选择器,要选择某个节点的后续兄弟节点,用 波浪线
xpath也可以选择 后续 兄弟节点,用这样的语法 following-sibling::
比如,要选择 class 为 singlechoice 的元素的所有后续兄弟节点 `//*[@class='singlechoice']/following-sibling::*`
等同于CSS选择器 .single_choice ~ *
如果,要选择后续节点中的div节点, 就应该这样写 //*[@class='single_choice']/following-sibling::div
xpath还可以选择 前面的 兄弟节点,用这样的语法 preceding-sibling::
比如,要选择 class 为 single_choice 的元素的 所有 前面的兄弟节点,这样写
//*[@class='single_choice']/preceding-sibling::*
要选择 class 为 single_choice 的元素的
前面最靠近的兄弟节点 , 这样写
//*[@class='single_choice']/preceding-sibling::*[1]
前面第2靠近的兄弟节点 , 这样写
//*[@class='single_choice']/preceding-sibling::*[2]
而 CSS选择器 目前还没有方法选择 前面的 兄弟节点
要了解更多Xpath选择语法,可以点击这里,打开Xpath选择器参考手册
selenium 注意点
我们来看一个例子
我们的代码:
- 先选择示例网页中,id是china的元素
- 然后通过这个元素的WebElement对象,使用findelementsby_xpath,选择里面的p元素,
# 先寻找id是china的元素
china = wd.find_element(By.ID, 'china')
# 再选择该元素内部的p元素
elements = china.find_elements(By.XPATH, '//p')
# 打印结果
for element in elements:
print('----------------')
print(element.get_attribute('outerHTML'))
运行发现,打印的 不仅仅是 china内部的p元素, 而是所有的p元素。
要在某个元素内部使用xpath选择元素, 需要 在xpath表达式最前面加个点 。
像这样
elements = china.find_elements(By.XPATH, './/p')
完活。